Tag Archive for 'copyright'
Published Mike Schnoor 03.03.2007, 11:27
in Rechtliches, Web 2.0 and Blogosphere.
Wie im offiziellen Weblog der Creative Commons nachzulesen ist, gibt es die zusätzliche Lizenzvergabe für Inhalte jeglicher Art seit kurzem in einer neuen Version.
Vorerst jedoch ist die Version 3 nur für die englischsprachige Lizenz vergeben - ein kleiner Test hat mir gezeigt, dass die deutsche Juristriktion noch ein Resultat basierend auf der 2er herausgibt… die deutsche Seite ist sowieso ein wenig mau und nicht wirklich aktuell.
P.S.: Ich möchte nocheinmal darauf betonen, dass die Inhalte dieses Weblogs ganz bewußt nicht unter einer CC-Lizenz laufen. Die Gründe finden sich hier, dort und in jenem Beitrag. Gerne zeige ich auch das als Gründe auf, welche im Herzen des Telagon Sichelputzer schon des öfteren genervte Reaktionen auf Contentdiebstahl hervorruften. Seitdem ich die CC nicht mehr verwendet hatte, waren es weniger Aggregatoren und Bots, die sich meine Inhalte zu eigen machen wollten. Das Zitatsrecht im Sinne des Urheberrechts ist natürlich etwas ganz anderes und wird von mir aktiv unterstützt - doch eine generelle Pauschalisierung von Inhalten sehe ich nicht als zwanghaft an. Gut, wenn es jemand macht - aber ich habe keinen Bock auf Abmahntouren, die im Fall eines Verstoßes gegen eine CC-Lizenz den Contentdieben einen temporären Riegel vorschieben würden.;)
Published Mike Schnoor 05.09.2006, 21:06
in Rechtliches, Web 2.0 and Medien.
Wer sich nicht unbedingt im Web 2.0 auskennt, der redet eher weniger von Technorati, Blogpulse, Blogscout und was man nicht alles nutzt, um durch das dynamischere Web zu browsen. Anstelle dieser jungen Dienstleistungen macht man eines, was nahezu jeder in unserer heutigen Zeit kann: Googeln mit Google!

Das Wort “Googeln” bzw. das englische “to google” beschreibt für den modernen Menschen die Suche nach Informationen im Internet. Doch das Multimillionendollar Unternehmen Google stört sich daran, dass der Begriff als Synonym für seine ureigentliche Aufgabe, das Durchsuchen und Indizieren von Webseiten und demnach aufbereiten in eine Ergebnisliste, von den Menschen genutzt wird. Selbst ein Eintrag durch das Oxford English Dictionary wurde per Richterspruch untersagt:
In June, Google won a place in the Oxford English Dictionary, while “to google”, with a lower case “g”, was included last month in Merriam-Webster’s Collegiate Dictionary, America’s leading reference book.
Was für ein Unsinn, wenn man ja bedenkt, dass der Suchmaschinengigant sich selbst immer mit dem (inoffiziellen) Slogan “don’t be evil” einbalsamiert. Zumindest jetzt kann man im Merriam-Webster Online Dictionary folgendes lesen:
Main Entry: goo·gle
Pronunciation: ‘gü-g&l
Function: transitive verb
Inflected Form(s): goo·gled; goo·gling /-g(&-) li[ng]/
Usage: often capitalized
Etymology: Google, trademark for a search engine
: to use the Google search engine to obtain information about (as a person) on the World Wide Web
Man sieht eine Anpassung des ursprünglichen Eintrages, der sich auf das “to google” auf allgemeines Suchen im Internet bezog. Wer also “googled”, bezieht sich laut Eintrag auf den Dienstleister Google, aber nicht mehr das allgemeine Suchen. Damit zeigt sich die Firma Google auch zufrieden.
Was wäre also, wenn man nun wirklich alles und jedes gegenprüfen müsste, bevor man darüber spricht? Wir kennen es doch schon, dass man ein wenig “flickrt“, öfters mal vielleicht sogar “bloggt” oder “browst“? Die Beispiele sind zwar an den Haaren herangezogen, doch wenn sich daraus ein Trend für Unternehmen herauskristallisiert, dass man sogar vom Prinzip her gegen seine eigenen Nutzer vorgeht - dann reicht sowas. Soll mir der Mund verboten werden, wenn ich offen zugebe, dass ich mal am googeln bin? In dem englischsprachigen Fall von der Firma “Hoover” für das Staubsaugen oder “Xerox” als Synonym zum Kopieren hatte man es irgendwie geschafft, den Begriff zu akzeptieren und nicht durch Rechtstreitigkeiten auch noch Schlagzeilen zu machen. Doch auch ich sehe soetwas natürlich im Sinne des Markenschutzes sehr gerechtfertigt, dass man Bedenken gegen einen solchen Eintrag oder überhaupt den Missbrauch der eigenen Marke hat. Aber im Fall von Google ist das nur ein weiterer beklemmender Griff des Kraken Googleopus - im Ende wohl mehr nicht als ein heißer Luftballon, der zu zerplatzen droht.
Published Mike Schnoor 05.09.2006, 15:13
in Spam and Rechtliches.
So schnell kann es gehen. Wie Andreas uns im Kommentar darauf hinwies, ist das Thema Weblog-Pla.Net wohl vorerst erledigt. Denn dieser miese dreiste freche arrogante Contentdieb hat vorerst, vielleicht sogar endlich, womöglich für immer ausgediebt.
This Account Has Been Suspended
Please contact the billing/support department as soon as possible.
Sein Hoster hat kurzerhand den Server abgeklemmt, weil wohl jemand nicht die Rechnungen bezahlt hat. Spammen will gelernt sein, und wer es richtig machen will, der zahlt auch fleissig - zumindest beim eigenen Hoster.
Published Mike Schnoor 24.08.2006, 12:29
in Spam.
Ein ganz windiger Contentdieb ist weblog-pla.net! Linkt nicht dorthin, denn dort wird fleissig geklaut, wie man an diesem Screenshot sieht:

Für die Zukunft habe ich in der .htaccess Datei auch gleich einen deny from 70.87.46.164 auf diesen dummen Sack gesetzt. Sowas kann ich nicht haben!
Published Mike Schnoor 19.08.2006, 09:10
in Spam, Rechtliches and Internes.
Wie hieß es damals so schön in den Star Wars Prequels? “Turmoil has engulfed the Galactic Republic.” Oder anders: “Turmoil has engulfed the Blogosphere.” Warum? Die Überschrift ist ja schon fast geschenkt, denn nach den Kommentaren bei Robert, bei Tom und auch in meiner ursprünglichen Ankündigung habe ich es mir doch einmal wieder reiflich überlegt, unsere Feeds zu kürzen. Die Reaktionen sind einerseits nachvollziehbar, wenn man insbesondere den Contentklau als Grund dieser Maßnahmenregelung hinzuzieht. Andererseits ist es auch teilweise pure Ablehnung, dass ein Feed gekürzt wird.
Das Problem ist einfach daran festzunageln, dass der normale Leser natürlich den Feed in voller Länge betrachten will. Ich selbst bevorzuge die längeren Feeds - was ich mir durch einen kleinen Blick in unsere dynamische Blogrolle oder meine ganze Feedliste wiederum vor Augen führte. Macht es also Sinn, den eigenen Feed zu kürzen, aber nur die Anbieter von Informationen im Volltext zu lesen? Irgendwie nicht. Daher werde ich nicht die Feeds kürzen, sondern mich eher auf die Suche nach einem brauchbaren “Guter Leser, Böser Bot” Plugin, Script oder sonstigem machen. Entschuldigung für meinen meta-viralen Opportunismus! Aber was soll man denn sonst gegen die Spamlinge und Contentdiebe unternehmen?! ;)
Published Mike Schnoor 18.08.2006, 17:54
in Spam and Internes.
Heute morgen waren wieder über 50 Spamversuche bei uns in der Queue. Eine Maßnahme dagegen war, dass ich manuell in der Datenbank ein generelles UPDATE auf alle älteren Beiträge durchführte und sämtliche Pingbacks, Trackbacks und Kommentare unterbinde. Dennoch sehe ich auch Handlungsbedarf im Zuge des Missbrauchs von unseren geistigen Ergüssen.
Ich finde es langsam auch verdächtig, nahezu dreist, ja geradezu ungehörig, dass gewisse Herrschaften die fremden Inhalte eines Blogs oder einer Webseite einfach kopieren. Das passiert nicht nur um damit direkt durch eine Kopie des Postings auch Geld zu verdienen, sondern führt dies zur Schädigung des eigenen Google Rankings oder der eigenen Inhalte, wenn massenweise gut gemachte Kopien im Internet umherschwimmen.
Ich werde auch wie Robert diesen Schritt in der kommenden Woche einleiten, und unsere RSS Feeds nur noch als Anreisser darzustellen. Sicherlich wird dieser Zug dem einen oder anderen Leser auf die Nerven gehen, aber mittlerweile finden sich zahlreiche unserer Beiträge in anderen Umgebungen wieder. Soetwas schmeckt uns nicht, soetwas gehört sich nicht. Und da man nicht Herr der Lage werden kann, wenn diese Leutchen in Osteuropa oder sonstwo stecken, schieben wir einfach den klassischen “No Go” Riegel davor. Bei Bedarf werden wir einen speziellen Feed für treue Leser mit Passwortabfrage anbieten, welche in modernen Feed Aggregatoren ohne weitere Probleme mit angegeben werden können. Das kommt aber auch nur in einem ernsthaften Bedarfsfall vor - nicht wenn ein Fremdling einfach danach hier jetzt fragt.
Published Mike Schnoor 30.06.2006, 08:56
in Rechtliches and Blogosphere.

Manchmal gibt es wieder unnütze Sachen, die ich ja ganz lustig finde. Copyscape ist einer dieser Dienstleister, die sich darauf spezialisiert haben, den Plagiarismus zu bekämpfen. Man gibt einfach die URL in deren Suchfeld ein und hofft darauf, am besten kein Suchergebnis zu bekommen - denn dann hat jemand den eigenen Content mal dreist kopiert. Ausnahmeerscheinungen wie Technorati sind natürlich auch gerne in den Suchergebnissen, aber wer weiß wozu es gut ist. Ob deren Präventivmaßnahme, einen Banner auf deren Seite zu schalten, auch irgendwen jemals davon abhalten sollte, die Inhalte zu kopieren, ist aber sehr sehr fragwürdig.
Published Mike Schnoor 13.04.2006, 18:14
in Design and Zukunft.
Ist Bilderklau leicht gemacht, wenn man seine eigens erstellten Bilder und Fotografien im Internet auf z.B. der eigenen Webseite, im Blog oder auf Bildersharing Dienstleistern platziert? Vom Prinzip her ist es einfach, aber im Endeffekt lässt sich sagen: Ganz und gar nicht - Bilderklau bleibt schwierig und hat auch manchmal (ungeahnte) Folgen mit dem Urheberrecht, sobald sich der Fotograf oder der Lizenzinhaber zu Wort meldet.
Gerade in den vergangenen Tagen gab es viel Wirbel um Bulls Pressedienst, aber auch ein Blogautor wie Don Alphonso hat so seine kleinen Probleme damit. Zuerst tauchen einige Spuren und Hinweise in den Kommentaren auf, dann stellt man fest, dass das eigene Bild geklaut und in einer unschönen Art verwendet wurde. Der Don schreibt deshalb eine schöne Rechnung, in der es sich zum Glück nicht um mehrere Tausend Euro, sondern doch nur 250 Tacken für sein Bild dreht. Nur was sich daraus entwickelt, ist wieder einmal ein schöner PR-Gau für die Berliner PR-Agentur Johanssen + Kretschmer… man darf also gespannt sein!
Abschließend noch zwei schöne Beispiele, was man machen sollte, um seine eigenen Bilder auf einfache Art und Weise zu schützen.
1. Der Dreiste Dieb
Dem Besitzer der Bilder bietet sich von vorn herein die Möglichkeit, die Daten vor dem sogenannten “Hotlinking” oder “aus Google Images runterladen” zu schützen, in dem in die .htaccess Datei auf dem Server beispielsweise folgender Code eingefügt wird:
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http://(www\.)?sichelputzer.de/.*$ [NC]
RewriteRule \.(gif|png|jpg)$ - [F]
So wird keines Bilder von anderen Servern verwendet - man kann auch alternativ eine “Weiterleitung” auf ein Bild (“>wie dieses hier) verwenden:
RewriteRule \.(gif|png|jpg)$ /wp-images/bilderklau.jpeg [L]
Vor einem direkten Download auf das Bild, was der dreiste Dieb in diesem Fall tuen sollte, schützt es aber nicht. Es dient nur dazu, um den eigenen Server vom Traffic zu entlasten, und kleinen “Scriptkiddies” den Gar auszumachen.
2. Geschicktes Branding
Für wirklich hochauflösendes Bildmaterial, was ein Fotograf zwar gerne zur Verfügung stellen möchte, aber aus Sicherheitsbedenken nicht unbedingt auf jeden Bilderdienst hochladen mag, gibt es das Branding. Das Bild wird hierbei mit einem kleinen Zusatz wie einem “digitalen Wasserzeichen” oder einfach einem gut sichtbaren Schriftzug dargestellt. Für die Weiterverwendung ist es dann meistens weniger sinnvoll, ein mit Schriftzug verunstaltetes Bild zu nutzen. Dennoch gibt es hierbei immer wieder Methoden, um auch das digitale Wasserzeichen oder das Schriftzug-Branding zu entfernen. Das kostet aber Zeit und Geld - und ein “otto-normal User” wird sicherlich nicht daran interessiert sein, das Bild so stark zu bearbeiten, dass dieses Branding komplett wegfällt.
Wer sonst noch Tipps und Tricks hat, um die eigenen Bilder zu schützen - immer her damit in die Kommentare. ;)
Published Mike Schnoor 29.01.2006, 22:09
in Familie.
Someone just stole my entire article and re-published it twice in his/her own blog! I filed in a complaint at the only place I’ve known for: Matt’s Blog at Wordpress.com!
Dear Matt,
since your domains are down, I try to reach you here in order to file in an abusive complaint about a wordpress.com user.
This post at “http://hadi.wordpress.com/2006/01/29/are-you-germany” is a 1-on-1 copy of one of my own ones at “http://www.sichelputzer.de/2006/01/29/you-are-germany/”!
I’d like to see that this copyright-thief is taking his/her copy of my article offline… if possible, please get back to me via the email provided in this comment!
Thank you and best regards,
Mike
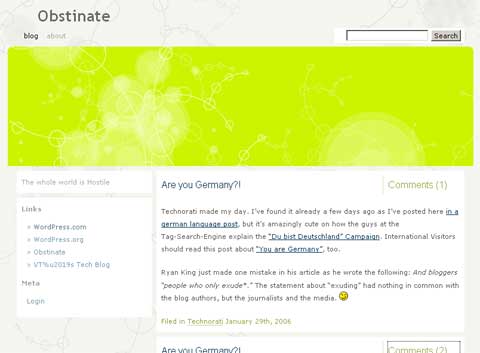
I hope that the content thief will be disallowed to use the content on the wordpress homepage, because it is my writing and my thoughts, and not the ideas of someone else.
Published Mike Schnoor 10.09.2005, 10:53
in Blogosphere.
I feel this is a “class C” post, since there’s a bunch of words that start with the letter C. Believe me! But for now the question for the weekend is cryptic? Cryptic! Duncan suspects content theft from his site. And according to him, these minions of darkness are other bloggers - who behave like copy cats. After setting up an article with a term of phrase which was simply grammatically incorrect, the same phrase appeared on his suspect’s content. That’s a fabulous search for all those who have nothing else to do on the weekend. Read on my dear and find out who the Staff Writer is. Plagiarism is on its way!
But besides talking about a cryptic copy cat, Duncan did one thing I’d like to slap him for. The URL to his original article is absolutely way too long… weekend-cryptic-question-which-leading-website-continues-to-steal-content-ideas-without-credit - oh my god! Wasn’t there some function in WordPress to cut off these lengthy post slugs?

